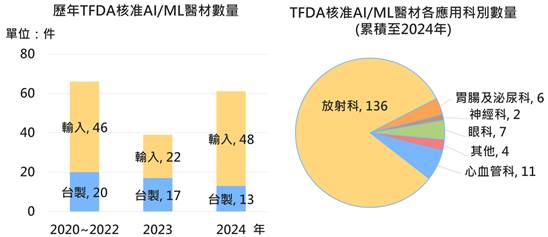
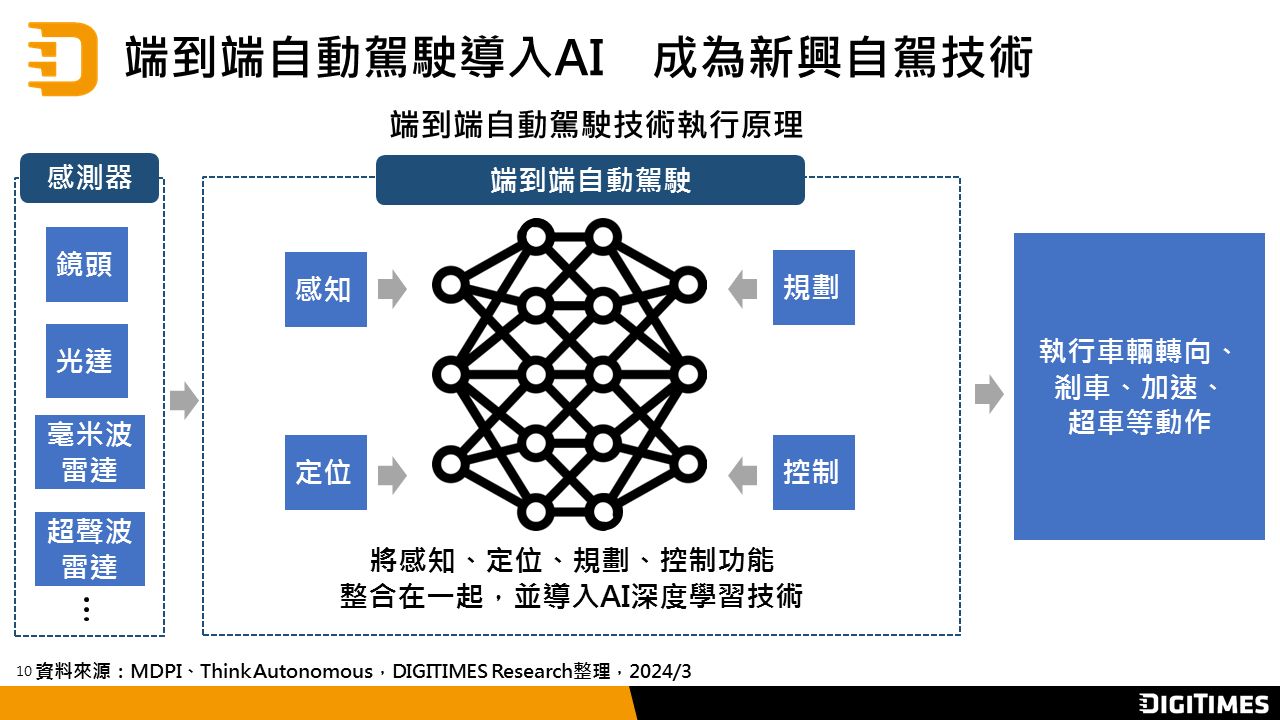
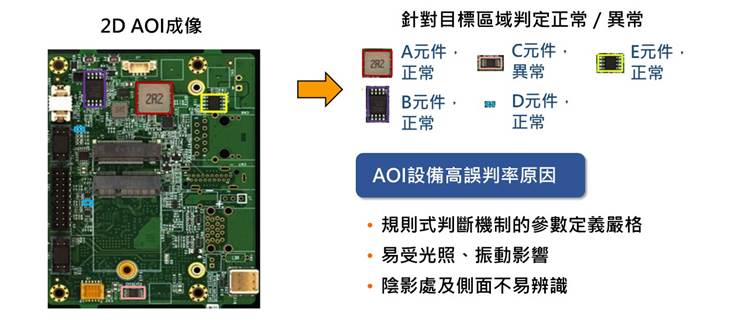
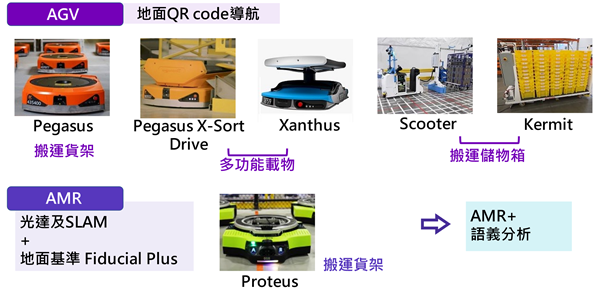
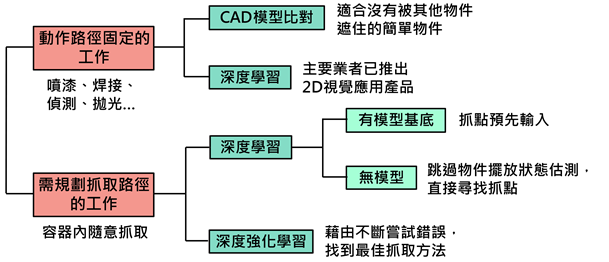
近年来自然语言处理(Natural Language Processing;NLP)兴起利用预训练(pre-training)架构,来产生具广泛语言认知能力的NLP语言模型(language model),由OpenAI于2020年5月所发表的第三代基于转换器(transformer)架构的生成式预训练(Generative Pre-trained Transformer;GPT) NLP语言模型GPT-3,是目前规模最大的跨领域通用NLP语言模型,借由提供应用程序界面(Application Programming Interface;API),已大幅提升开发NLP应用的便利性,可望尽早实现以自然语言作为人机沟通基础的目标,然OpenAI与微软(Microsoft)的合作关系对NLP技术垄断及对AI产业的影响程度值得持续观察。
预训练NLP语言模型自2018年初问世以来,随即成为该领域的发展主流。时至今日,预训练NLP语言模型的演算法差异不大,但其训练所需语料(corpus)数据及模型参数(parameter)规模却与日俱增。
日前由OpenAI发表的GPT-3 NLP语言模型已具有1,750亿个参数规模,其广泛通用性已可省去典型预训练架构的微调(fine-tuning)步骤,同时也降低NLP应用发展过程中对于标注数据的依赖。OpenAI基于AI安全性与商转需求,将不会公开GPT-3原始码,而透过API形式开放业界使用,将可增加NLP技术的易用性,降低一般企业或个人用户开发NLP应用的进入门槛。
值得注意的是,OpenAI为满足发展GPT-3庞大语言模型所需的可观运算资源,已于2019年转型成立营利机构,并获得微软独家投资,微软也于日前宣布取得GPT-3独家技术授权。DIGITIMES Research认为,尽管GPT-3未来发展仍须面临AI伦理及商转挑战,然其跨领域易用性可望加速NLP技术普及,而微软是否因取得GPT-3技术而垄断NLP发展,对于AI技术发展影响性可持续追踪。